|
I am a first year PhD. student at IIT Delhi, where I work in the Laboratory for Computational Social Systems (LCS2) lead by Dr. Tanmoy Chakraborty and Dr. Md. Shad Akhtar. My primary area of research includes understanding generalization capabilities of pre-trained language models, representation learning for code-mixed and low-resource languages. My other areas of interest are Bayesian meta learning and representation learning from knowledge graphs, graph neural network and generative NLP. I am also a Senior Data Scientist at Optum (UnitedHealth Group), where I work on building NLP solutions Optum's housecall program. Optum's housecall program provides in-house care for patients. As part of this initiative, we analyze patient call transcripts for pain point analysis and enable Optum to provide better experience for our customers. Before joining Optum, I completed my Masters in Business Analytics and Data Science (PGDBA) from Indian Institute of Management, Calcutta . Prior to that, I did my Masters of Science in Mathematics and Computing from Indian Institute of Technology, Guwahati in 2015 and Bachelor of Science in Mathematics and Computer Science from Chennai Mathematical Institute in 2013. Email / CV / GitHub / LinkedIn / Kaggle / Topcoder / Scholar |

|

|
|
|

|
Advisors: Dr. Tanmoy Chakraborty and Dr. Md. Shad Akhtar |

|
Advisors: Dr. Tanmoy Chakraborty and Dr. Md. Shad Akhtar Courses: Machine Learning, Natural Language Processing, Social Network Analysis, Data Mining, Artificial Intelligence, Bayesian Machine Learning |

|
Courses: Algorithms, Machine Learning, Multivariate Analysis, Complex Networks, Information Retrieval, Econometrics, Statistical Inference |

|
Advised by Prof. Anupam Saikia for masters thesis on Mathematics of Elliptic Curves and its application in Cryptography Courses: Algorithms, Logic Programming (Prolog, Introduction to AI), Probability Theory, Numerical Analysis, Optimization |

|
Courses: Mathematical Logic, Algorithm Design, Game Theory, Theory of Computation, Programming |
|
|
|
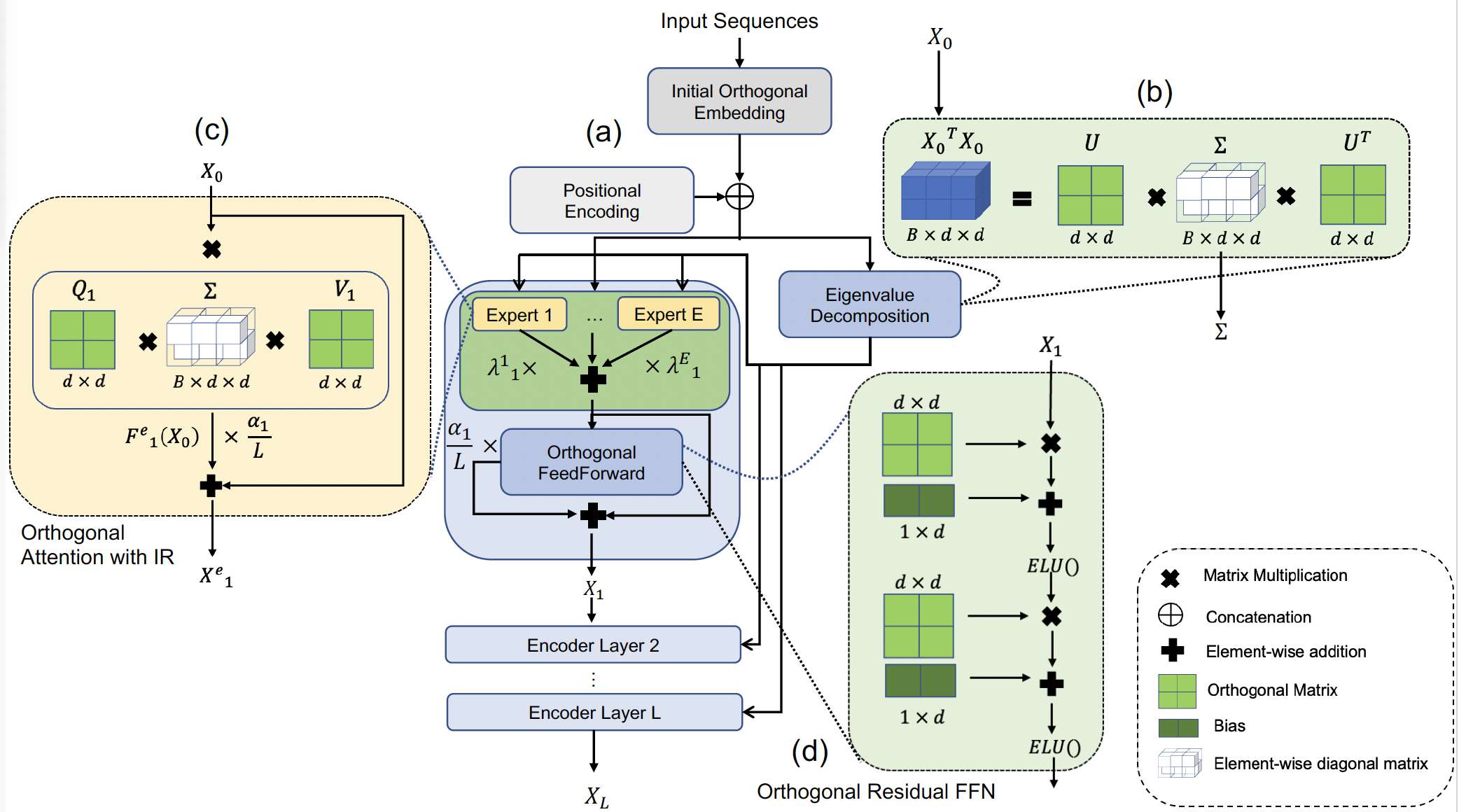
Multi-head self-attention-based Transformers have shown promise in different learning tasks. Albeit these models exhibit significant improvement in understanding short-term and long-term contexts from sequences, encoders of Transformers and their variants fail to preserve layer-wise contextual information. Transformers usually project tokens onto sparse manifolds and fail to preserve mathematical equivalence among the token representations. In this work, we propose TransJect, an encoder model that guarantees a theoretical bound for layer-wise distance preservation between a pair of tokens. We propose a simple alternative to dot-product attention to ensure Lipschitz continuity. This allows TransJect to learn injective mappings to transform token representations to different manifolds with similar topology and preserve Euclidean distance between every pair of tokens in subsequent layers. Evaluations across multiple benchmark short- and long-sequence classification tasks show maximum improvements of 6.8% and 5.9%, respectively, over the variants of Transformers. Additionally, TransJect displays 79% better performance than Transformer on the language modeling task. We further highlight the shortcomings of multi-head self-attention from the statistical physics viewpoint. Although multi-head self-attention was incepted to learn different abstraction levels within the networks, our empirical analyses suggest that different attention heads learn randomly and unorderly. In contrast, TransJect adapts a mixture of experts for regularization; these experts are more orderly and balanced and learn different sparse representations from the input sequences. TransJect exhibits very low entropy and can be efficiently scaled to larger depths. |

Image Credits: Link |
Aggression is a prominent trait of human beings that can affect social harmony in a negative way. The hate mongers misuse the freedom of speech in social media platforms to flood with their venomous comments in many forms. Identifying different traits of online offense is thus inevitable and the need of the hour. Existing studies usually handle one or two offense traits at a time, mainly due to the lack of a combined annotated dataset and a scientific study that provides insights into the relationship among the traits. In this paper, we study the relationship among five offense traits – aggression, hate, sarcasm, humor, and stance in Hinglish (Hindi-English) social media code-mixed texts. We employ various state-of-the-art deep learning systems at different morphological granularities for the classification across five offense traits. Our evaluation of the unified framework suggests performance across all major traits. Furthermore, we propose a novel notion of causal importance score to quantify the effect of different abusive keywords and the overall context on the offensiveness of the texts. |

Image Credits: Link |
Understanding linguistics and morphology of resource-scarce code-mixed texts remains a key challenge in text processing. Although word embedding comes in handy to support downstream tasks for low-resource languages, there are plenty of scopes in improving the quality of language representation particularly for code-mixed languages. In this paper, we propose HIT, a robust representation learning method for code-mixed texts. HIT is a hierarchical transformer-based framework that captures the semantic relationship among words and hierarchically learns the sentence-level semantics using a fused attention mechanism. HIT incorporates two attention modules, a multi-headed self-attention and an outer product attention module, and computes their weighted sum to obtain the attention weights. Our evaluation of HIT on one European (Spanish) and five Indic (Hindi, Bengali, Tamil, Telugu, and Malayalam) languages across four NLP tasks on eleven datasets suggests significant performance improvement against various state-of-the-art systems. We further show the adaptability of learned representation across tasks in a transfer learning setup (with and without fine-tuning). |

Image Credits: Link |
Robust sequence-to-sequence modelling is an essential task in the real world where the inputs are often noisy. Both user-generated and machine generated inputs contain various kinds of noises in the form of spelling mistakes, grammatical errors, character recognition errors, all of which impact downstream tasks and affect interpretability of texts. In this work, we devise a novel sequence-to-sequence architecture for detecting and correcting different real world and artificial noises (adversarial attacks) from English texts. Towards that we propose a modified Transformer-based encoder-decoder architecture that uses a gating mechanism to detect types of corrections required and accordingly corrects texts. Experimental results show that our gated architecture with pre-trained language models perform significantly better that the non-gated counterparts and other state-of-the-art error correction models in correcting spelling and grammatical errors. Extrinsic evaluation of our model on Machine Translation (MT) and Summarization tasks show the competitive performance of the model against other generative sequence-to-sequence models under noisy inputs. |
Image Credits: Link |
Short text is a popular avenue of sharing feedback, opinions and reviews on social media, e-commerce platforms, etc. Many companies need to extract meaningful information (which may include thematic content as well as semantic polarity) out of such short texts to understand users’ behaviour. However, obtaining high quality sentiment-associated and human interpretable themes still remains a challenge for short texts. In this paper we develop ELJST, an embedding enhanced generative joint sentiment-topic model that can discover more coherent and diverse topics from short texts. It uses Markov Random Field Regularizer that can be seen as generalisation of skip-gram based models. Further, it can leverage higher order semantic information appearing in word embedding, such as self-attention weights in graphical models. Our results show an average improvement of 10% in topic coherence and 5% in topic diversification over baselines. Finally, ELJST helps understand users' behaviour at more granular levels which can be explained. All these can bring significant values to service and healthcare industries often dealing with customers. |

|
This document describes the system description developed by team datamafia at WNUT-2020 Task 2: Identification of informative COVID-19 English Tweets. This paper contains a thorough study of pre-trained language models on downstream binary classification task over noisy user generated Twitter data. The solution submitted to final test leaderboard is a fine tuned RoBERTa model which achieves F1 score of 90.8% and 89.4% on the dev and test data respectively. In the later part, we explore several techniques for injecting regularization explicitly into language models to generalize predictions over noisy data. Our experiments show that adding regularizations to RoBERTa pre-trained model can be very robust to data and annotation noises and can improve overall performance by more than 1.2%. |
|
|

|
|

|
|
|
|

Image Credits: Link |
Built deep learning based multi-task model for disease prediction. We utilized clinical knowledge graphs and tempo-spatial representation for encounter level predictions of diagnosis and medications. |

Image Credits: Link |
Building information extraction engine to extract structured information from noisy scanned images of handwritten medical charts. Our solution involves multi-modal system to first detect the type of chart page, given the image and OCR text. Further we use sequential and transformer models to detect named entities from noisy word tokens and parse the text into key-value pairs. Our solution can be used for extracting demographic information as well as, key medical conditions from unstructured texts. |

Image Credits: Link |
In this project we develop an end-to-end system that extracts meaningful and actionable pain points from user generated texts like - feedback, complaint, social media feeds, telecommunications etc. Our solution extracts customers' intent at topic level and prioritizes critical issues in an unsupervised manner. We use probabilistic generative models based on Latent Dirichlet Allocation (LDA) to detect joint topic-sentiments from texts. Further, we use statistical measures to quantify information content and assign a priority score to each complaint so that the downstream CRM teams can be assigned accordingly. We also developed a NMF (Non-Negative Matrix Factorization) based online version of our solution to work with high velocity streaming data. |
|
|
|

|
Code-mixing is very common in social media. In this project, we learned textual representation from Hinglish, Tamil-English and Malayalam-English texts and further classify its sentiment. We learned unsupervised word embeddings - word2vec, fastText and contextual embeddings using BERT and used sequential attention models and BERT for classifying tweet sentiment. We further used BytePairEncoding (BPE) and learned representation using custom transformers from scratch. |

|
In this project we developed a named entity recognition system to detect pharmaceutical entities from Spanish clinical corpus. We explored different embedding techniques along with sequential and convolutional models with conditional random field (CRF) for classifying entities and detecting entity offsets. |
|
|

|
In this challenge, the participants were asked to write an essay on one of the following seven chosen topics from the field of AI, with a prompt to describe what the community has learned over the past 2 years of working and experimenting with.
|

|
In this challenge, the objective is to classify whether a comment is toxic (or, abusive). The dataset contains multi-lingual comments from different Wikipedia talk pages. We experimented with various multilingual transformer models, Universal Sentence Encoder (USE) and their ensembles.
|
|
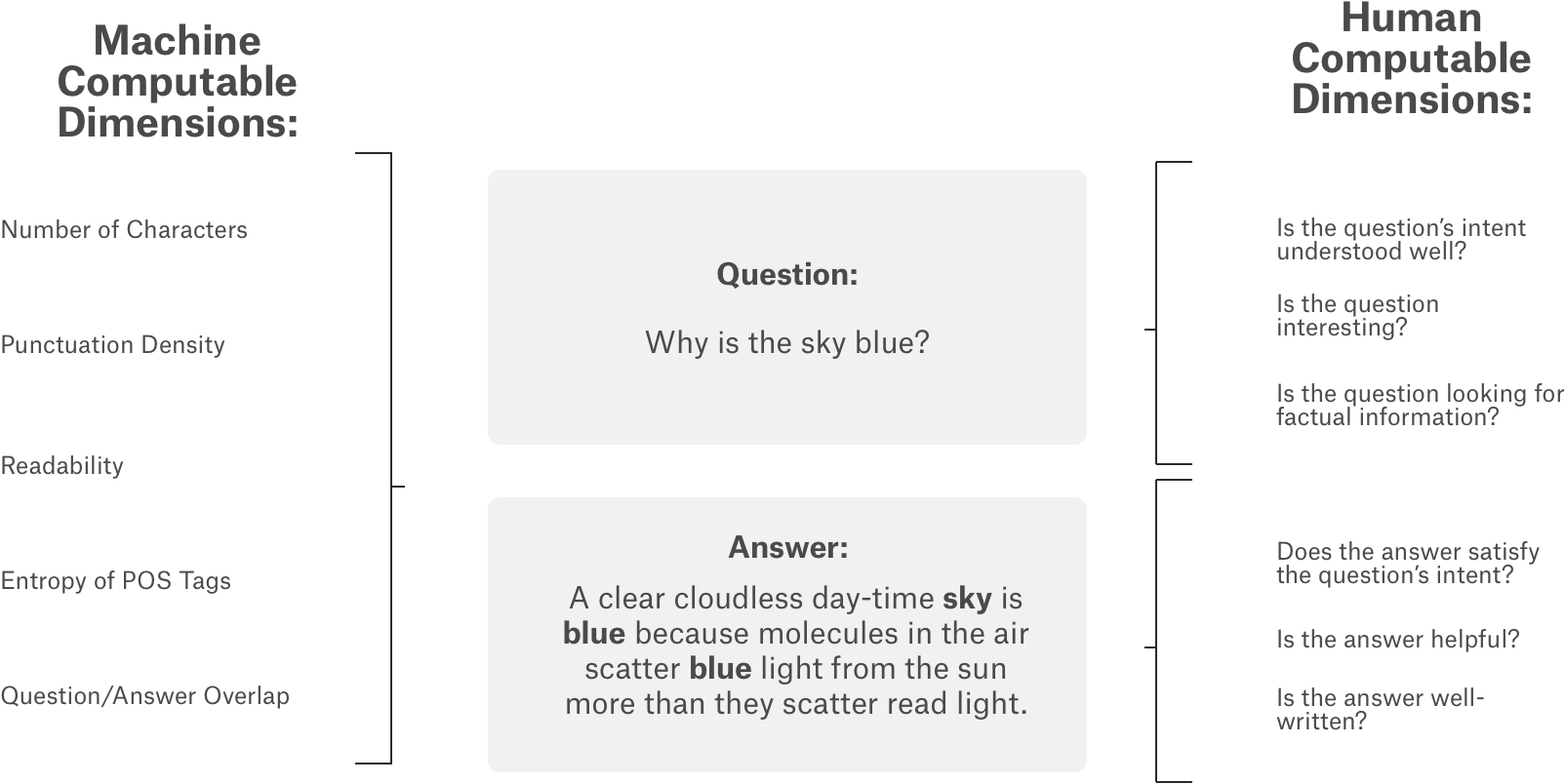
In this challenge, the objective is to predict different subjective aspects of question-answering gathered from different StackExchange properties. In this competition, we explored BERT model and hand picked feature engineering to develop a robust model that can predict the subjectivity metrics accurately.
|
|
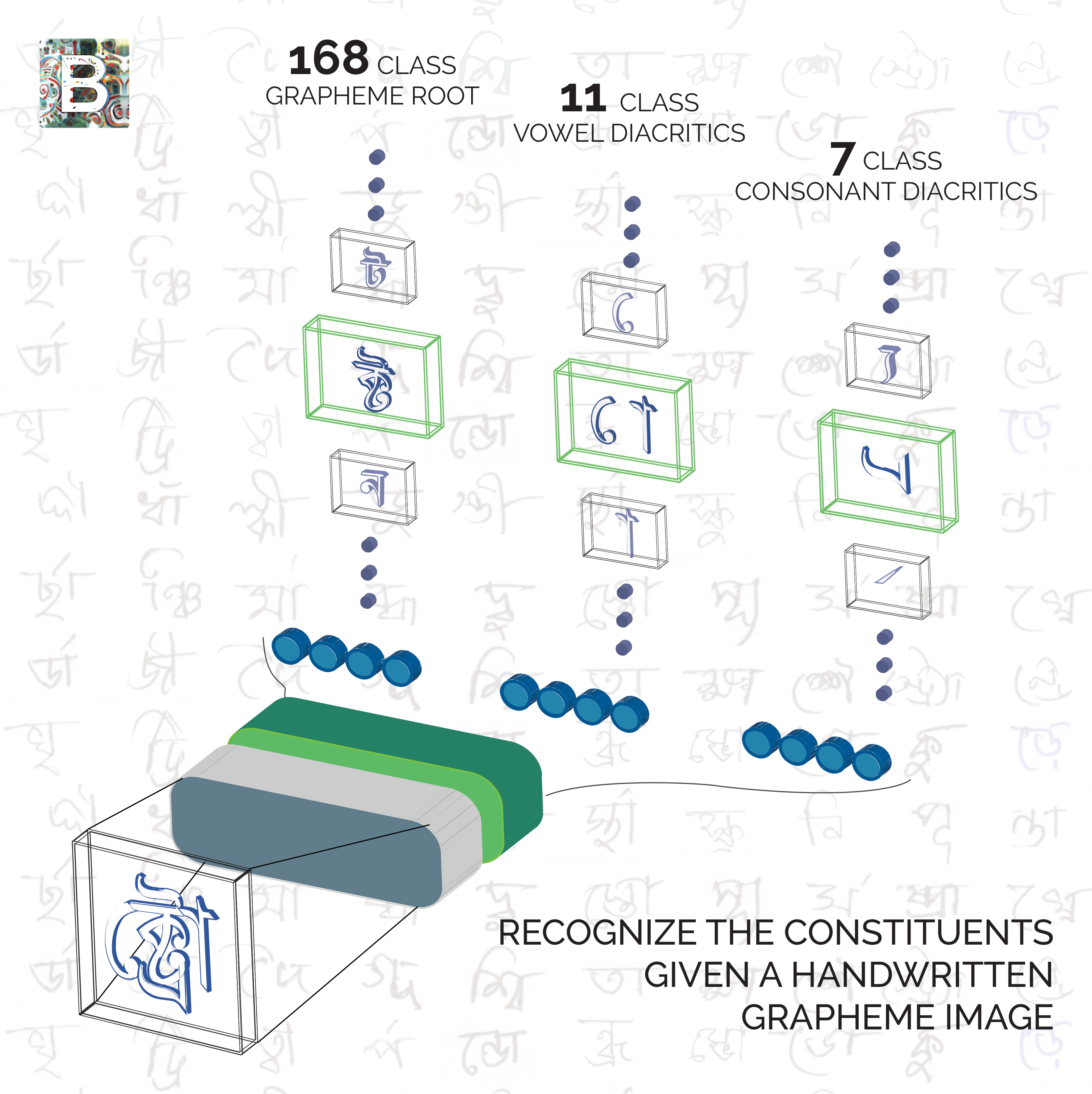
Experimented with efficient net models with different CNN heads (SSE, GEM pooling) on GPU/TPU to classify handwritten bengali alphabets and its constituents (diacritics).
|
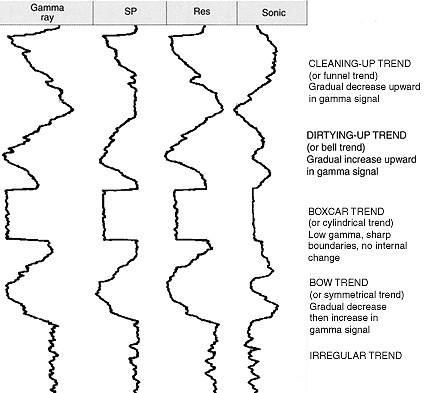
Image Credits: Link |
Given an array of GR (Gamma-Ray) values, accurately predict the log facies type corresponding to each value. Solution includes stacking of several seq2seq models with attention. Achieved overall 96.8% accuracy.
|

|
The competition focused on fine grained classification of objects from aerial imagery. We used different image augmentation techniques along with different image classification models - MobileNet, Resnet, InceptionNet and achieved average precision of 55% on the test data.
|

Image Credits: Link |
The challenge was to classify orientation of building roofs using satellite images of roof tops. We used different image augmentation techniques along with VGG network and achieved 82% accuracy on test dataset.
|
|
|

Image Credits: Link |
A consolidated NLP toolkit for text data analysis and modeling. It supports various functionalities like - tokenization, lemmatization, binary/multiclass classification, sequence classification, Question-Answering, Natural Language Inference (NLI) training as well as inference. It supports CPU/GPU/TPU platforms. |
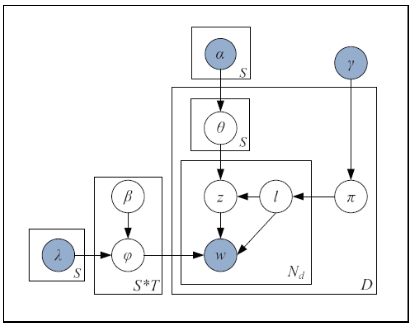
|
Joint topic-sentiment models aka. aspect rating models can extract thematic representation from texts at a granular level. In the areas of customer relationship management, it is utmost important to understand the pain point areas of customers from their feedbacks, complaints data and other data sources. By leveraging both sentiment as well as, thematic information, JST based models can understand the intent at overall level as well as, at theme level, which makes it perfect for analyzing voice of the customers.
|

|
This is a simple slack bot that reads the required product description from the users, parses the user input and shows relevant products from Amazon. |
|
|
|
|
|
Thanks to Jon Barron and Bodhisattwa P. Majumder for this nice template. |